As EU sustainability reporting requirements began mandating emissions disclosure across the food and beverage industry, companies found themselves under pressure to collect accurate, primary carbon data from their entire supply chain. Retailers and wholesalers, now obligated to report product-level emissions, needed a reliable way to gather that data from their network of producers and suppliers, at scale and with verifiable accuracy.
This project addresses that gap by designing a centralized platform that enables these organizations to request, collect, and validate primary emissions data directly from suppliers, replacing the fragmented email-based processes that were failing to meet the new demands.
Organizations struggle to calculate accurate product-level carbon emissions due to:
01
Reliance on estimated or secondary data
02
Disconnected communication channels with suppliers
03
Inconsistent and incomplete data submissions
04
High operational overhead in managing outreach and follow-up
In the food and beverage industry, where supply chains span multiple tiers and hundreds of suppliers, these challenges are amplified by the sheer volume of actors involved and the varying levels of data maturity across them.
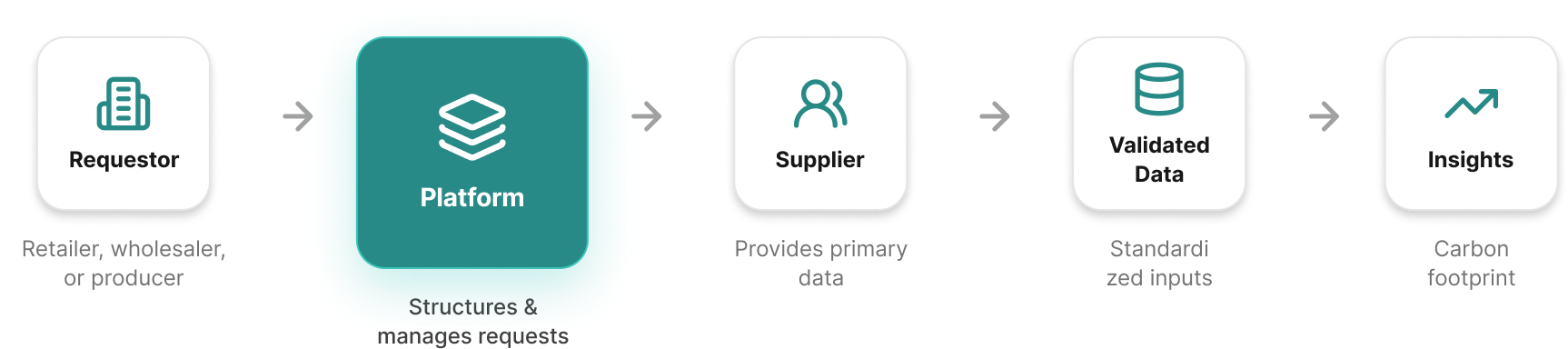
To address the fragmented and manual nature of carbon data collection, I designed a centralized platform that enables retailers, wholesalers, and producers to request, collect, and validate primary emissions data directly from their suppliers.
Instead of relying on emails, spreadsheets, and inconsistent documentation, the solution introduces a structured, end-to-end system that standardizes how data is gathered while remaining flexible enough to accommodate the complexity of real-world supply chains. The platform connects multiple actors across the supply chain through a shared workflow, ensuring data flows consistently from request to validation to insight.
Design Principles
Several key principles guided the design of the system:
Standardization without rigidity: Data is structured to ensure consistency, while still allowing flexibility for different supplier contexts and levels of data maturity.
Minimizing supplier effort: The experience is designed to reduce friction through clear guidance, intuitive inputs, and the ability to complete requests progressively.
Data quality by design: Validation is embedded into the experience, preventing errors and gaps rather than relying on manual correction later.
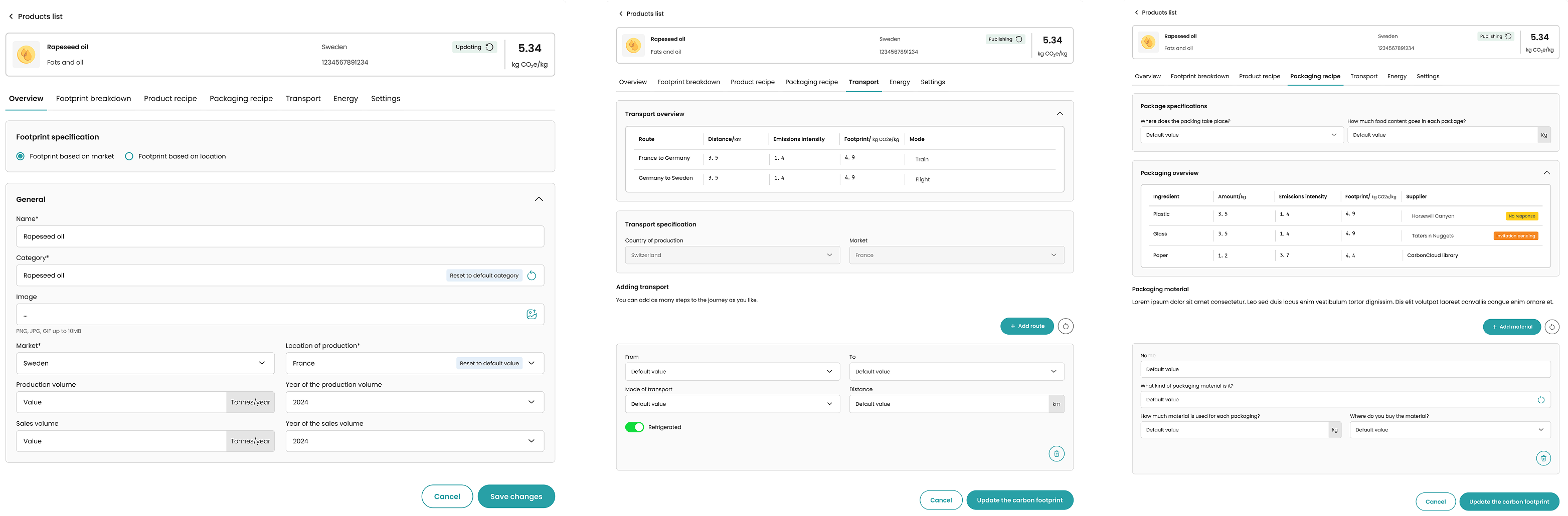
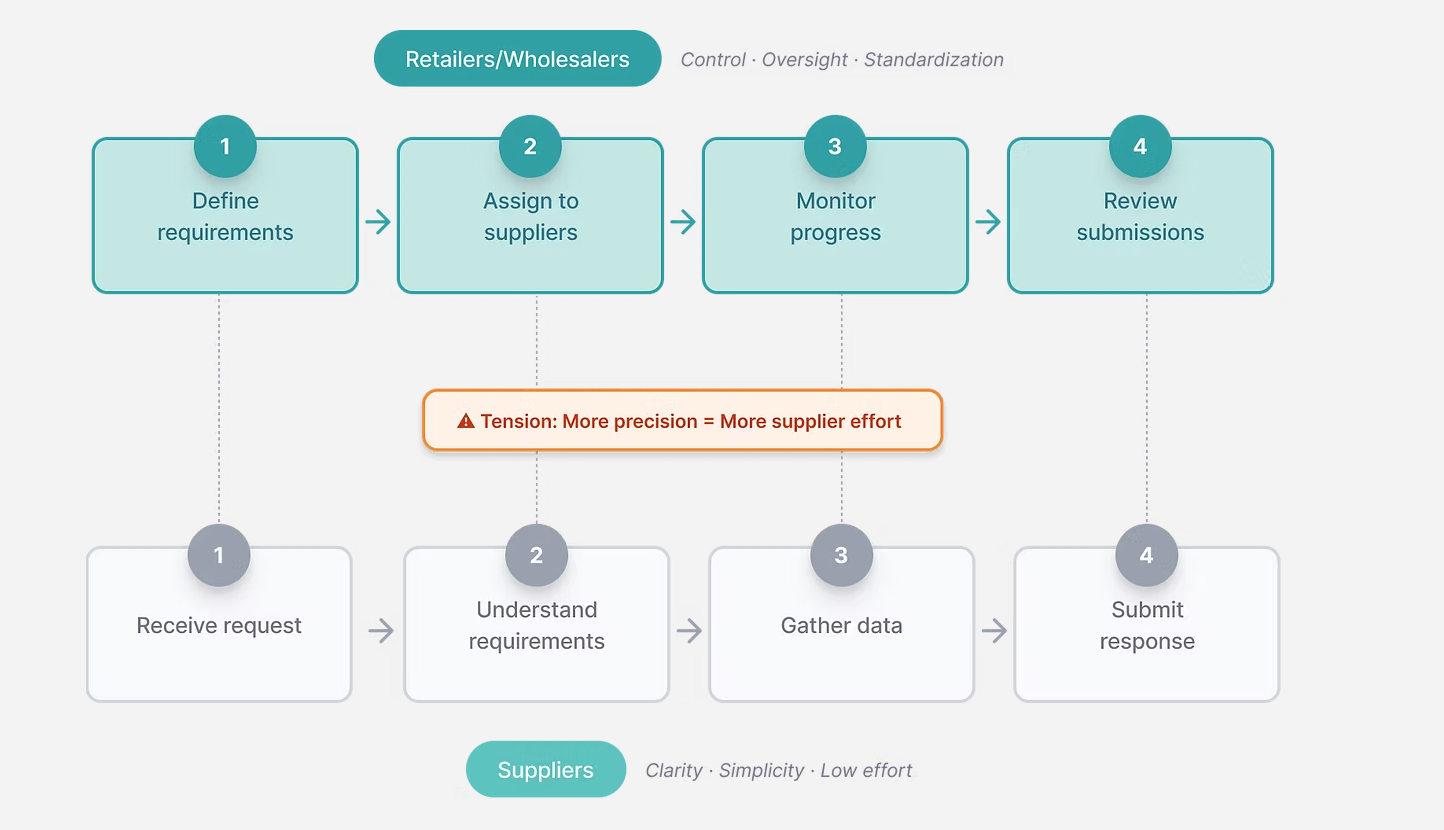
Applying these principles required balancing structure with usability. Stricter inputs improve data quality, but they can also increase friction and reduce completion rates. The solution addresses this by combining standardized formats with flexible input options, letting suppliers provide accurate data without unnecessary barriers.
01
Mapping a complex ecosystem
I began by mapping the relationships between retailers, wholesalers, and suppliers to understand how carbon data moves across the supply chain. This helped identify key actors, dependencies, and points where data collection typically breaks down. One challenge that emerged early was the depth of the supply chain itself. Food supply chains can involve many intermediary parties between retailer and producer, making it difficult to trace exactly where the relevant data sits and who is responsible for providing it.
Key decision
I focused on enabling primary data collection directly from suppliers rather than relying on secondary estimates.
Why
Primary data improves accuracy and builds a more reliable foundation for sustainability reporting.
02
Breaking down the data problem
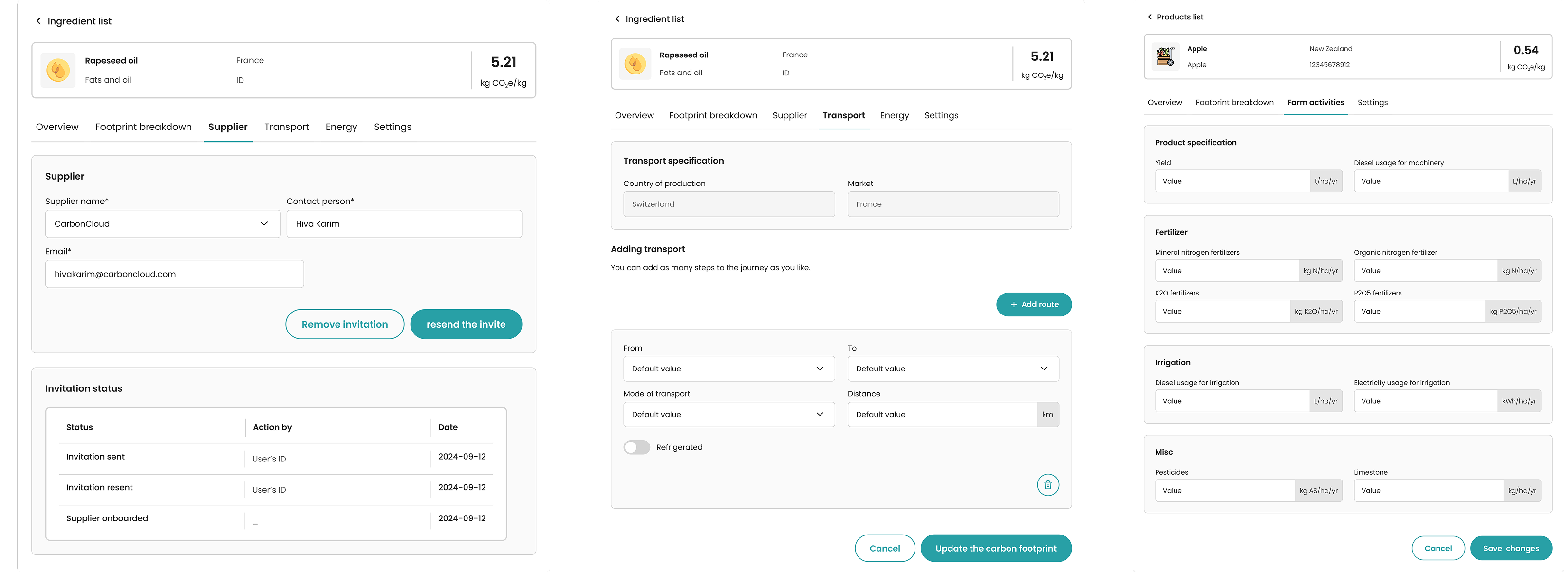
Early on I found that suppliers were reporting the same type of data in completely different ways: one using kg CO₂e per kg of product, another providing total annual figures with no product-level breakdown, and some sending unstructured spreadsheets or PDFs. Without a shared definition of what was needed and in what format, every submission required manual interpretation before it could be used.
Key decision
I defined a common data schema: specifying exactly what inputs were required, in which units, and at what level of granularity.
Why
Standardization reduces ambiguity, improves consistency, and makes the system scalable across different supply chains.
03
Designing the request-response flow
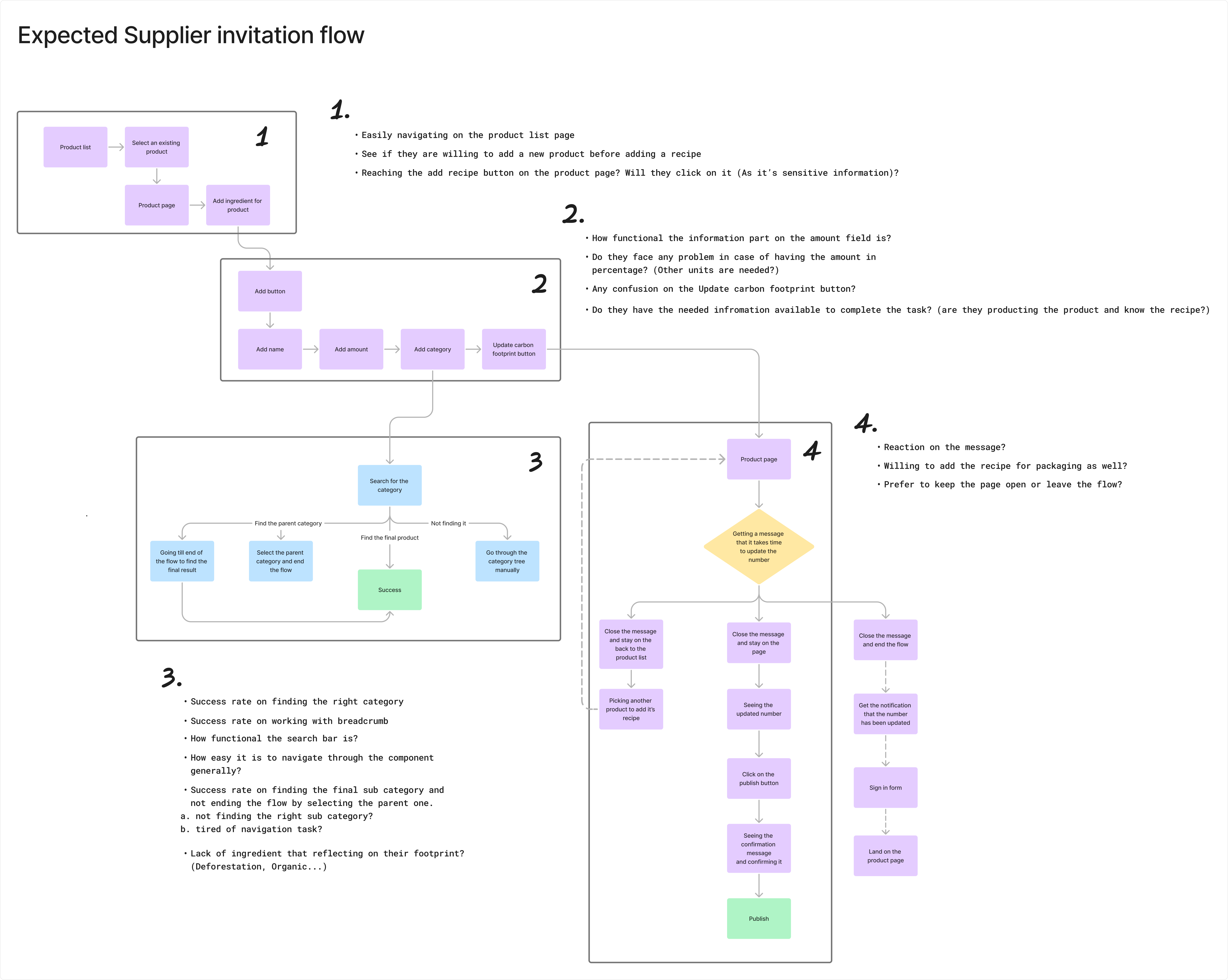
I designed a structured workflow where retailers create and send data requests, and suppliers respond through a guided submission experience. A significant constraint during this phase was that many producers were reluctant to share recipe data, concerned about exposing proprietary formulations. This meant the system needed to build in explicit privacy assurances and clear communication about data handling, not as an afterthought but as a core part of the request experience. To validate the flow before building, I ran usability tests with both user groups, mapping four key task scenarios and tracking where users succeeded, hesitated, or dropped off. Beyond the individual request flow, I also designed the broader management layer, giving teams a centralized view to track multiple suppliers, monitor response rates, and identify gaps in real time.
Key decision
I separated the experience into two distinct flows: one for requesting data and one for submitting it.
Why
This reduces cognitive load for each user group and allows the interface to better support their specific goals and contexts.
04
Reducing supplier friction
Recognizing that many suppliers may not be sustainability experts, I focused on making the submission process as intuitive and approachable as possible.
Key decision
I used a step-by-step flow with progressive disclosure instead of presenting all fields at once.
Why
This reduces overwhelm, simplifies complex inputs, and increases the likelihood of completion.
01
Structured data request
A standardized system for defining and sending carbon data requirements to suppliers, ensuring clarity and consistency across all requests.
Impact
Reduces ambiguity and improves the quality of incoming data.
Retailers define carbon data requirements using standardized fields and clear input definitions, ensuring consistency across all supplier submissions.
02
Guided supplier submission flow
A step-by-step experience that simplifies complex data entry and supports suppliers regardless of their level of expertise.
Impact
Increases completion rates and lowers the barrier to participation.
A step-by-step submission experience breaks down complex data entry into manageable steps, reducing cognitive load and improving completion rates.
03
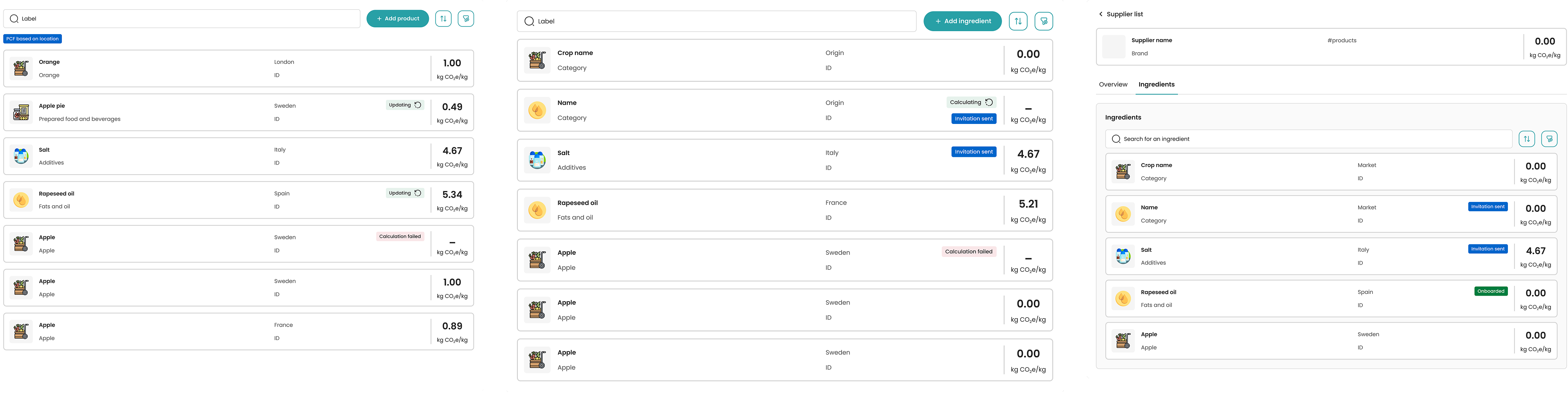
Centralized data tracking
A unified view of all requests and their progress across suppliers, enabling teams to monitor completion and identify gaps in real time.
Impact
Improves visibility and reduces reliance on manual tracking.
A unified dashboard provides real-time visibility into request status across suppliers, enabling teams to monitor progress and quickly identify missing data.
04
Flexible data structure
A data model built to handle suppliers at different stages of reporting maturity: from detailed product-level emissions to partial or estimated inputs, without compromising the integrity of the overall collection.
Impact
Ensures the product can adapt to complex and evolving supply chain needs.
05
Automated follow-ups
Progress-aware reminders triggered by submission status and deadline proximity, so follow-up reaches suppliers at the right moment rather than on a fixed schedule.
Impact
Reduces manual effort and improves response rates.
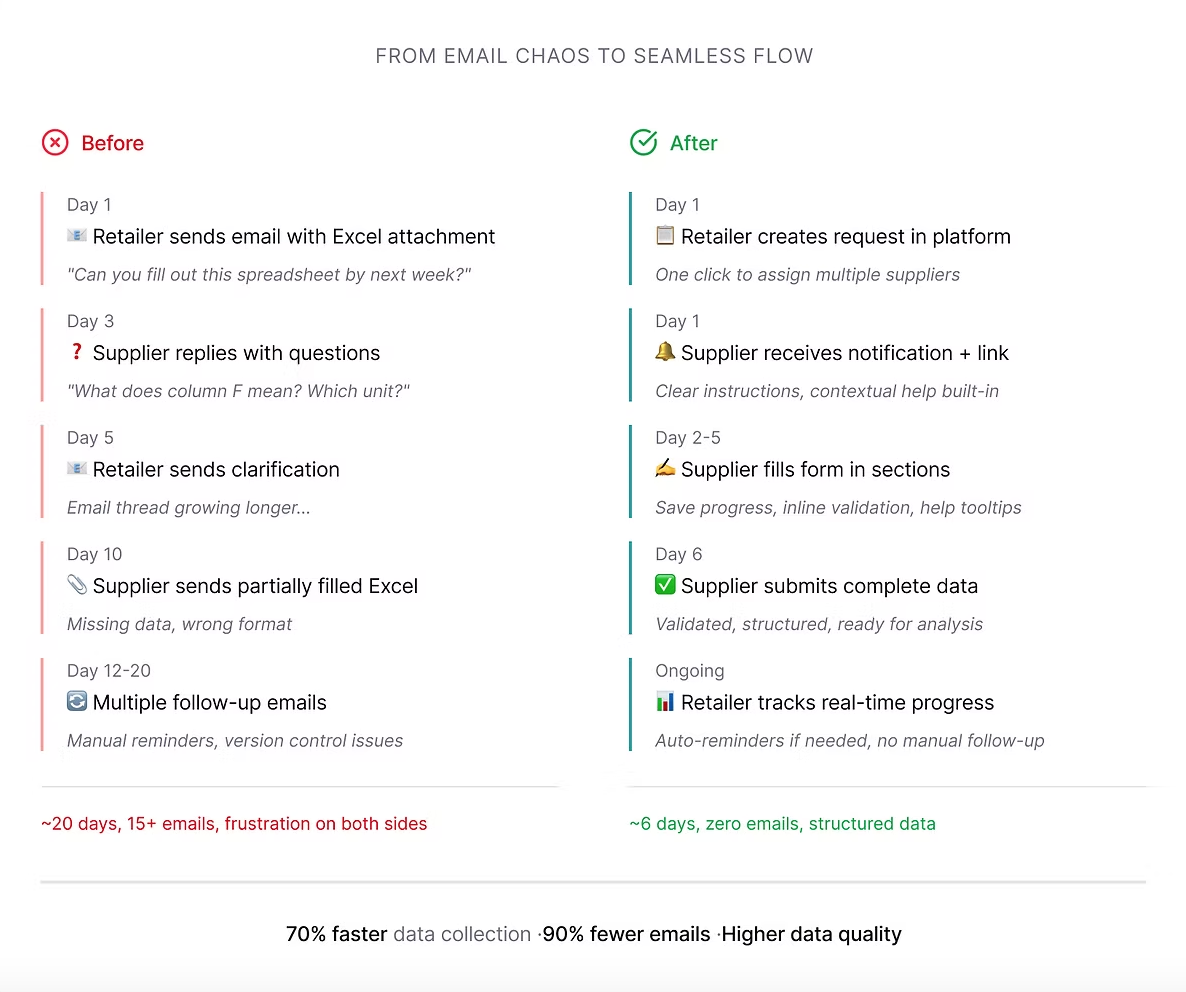
This project introduced a more structured and scalable approach to collecting carbon emissions data across complex food supply chains, improving both the reliability of data and the efficiency of the collection process. Suppliers who previously required multiple follow-up emails were completing requests independently within the platform, reducing coordination overhead for the teams managing collection.
9/10
Test users rated the submission flow as easy to work with
100+
Suppliers onboarded in the first production round
+1 yr
Engagement extended beyond the initial contract scope
L1
Designing for complex systems means working beyond the interface
Working across a multi-actor ecosystem revealed that the hardest design problems weren't about screens. They were about data structure, actor relationships, and how the product behaves at scale. Bringing clarity to ambiguous and inconsistent data environments was as important as any interaction design decision.
Next step
Define a more robust handling model for supplier types that don't fit the current data schema, focusing on edge cases that reveal where the system's structure needs to grow.
L2
User experience must balance simplicity and flexibility
One of the key challenges was designing for both novice and advanced users. Simplification is critical for supplier adoption, but progressive disclosure, breaking the process into guided steps, also proved essential for reducing cognitive load without removing the depth that experienced users need.
Next step
Test whether role-based onboarding that distinguishes novice from experienced suppliers upfront reduces drop-off in the first submission step.
L3
Primary data collection introduces trade-offs worth designing for
Shifting from estimated to primary data improves accuracy, but also introduces real friction for suppliers. Balancing data quality with ease of input is not a one-time design decision. It's an ongoing tension that needs to be revisited as the supplier base grows.
Next step
Investigate pre-populated fields based on supplier category or historical submissions to reduce input burden without sacrificing accuracy.
If I were starting this project again, I would involve suppliers in the discovery phase much earlier. Not just as usability test participants, but as active contributors to defining what a good data request looks like from their side. Many of the friction points we discovered during testing could have shaped the design direction from the start, rather than being addressed through iteration.